

Data quality is always a potential issue lurking around in unfamiliar datasets or hiding in data that has been summarized. To combat these issues, knowing what they are and how to detect them is critical to keeping your datasets accurate so you can be confident in the insights you discover.
Some of the more common data quality issues include missing data from a row or column, duplicate records, incorrect values, inconsistent formatting, and referential integrity (i.e., data linked across tables). Timing can also affect data quality, especially when performing analyses across multiple tables, as data loads can be late or inconsistent refresh schedules.
Bad data can, and often does, lead to bad business decisions, but sometimes worse than that is that when users find data issues and make bad business decisions, they may lose trust in the entire data environment or BI system. This in turn erodes the ROI and the adoption of the assets built. An IBM study in 2018 found that the cost of data quality issues in the U.S. amounted to $3.1 trillion.
Here are some simple examples of what bad data might look like:
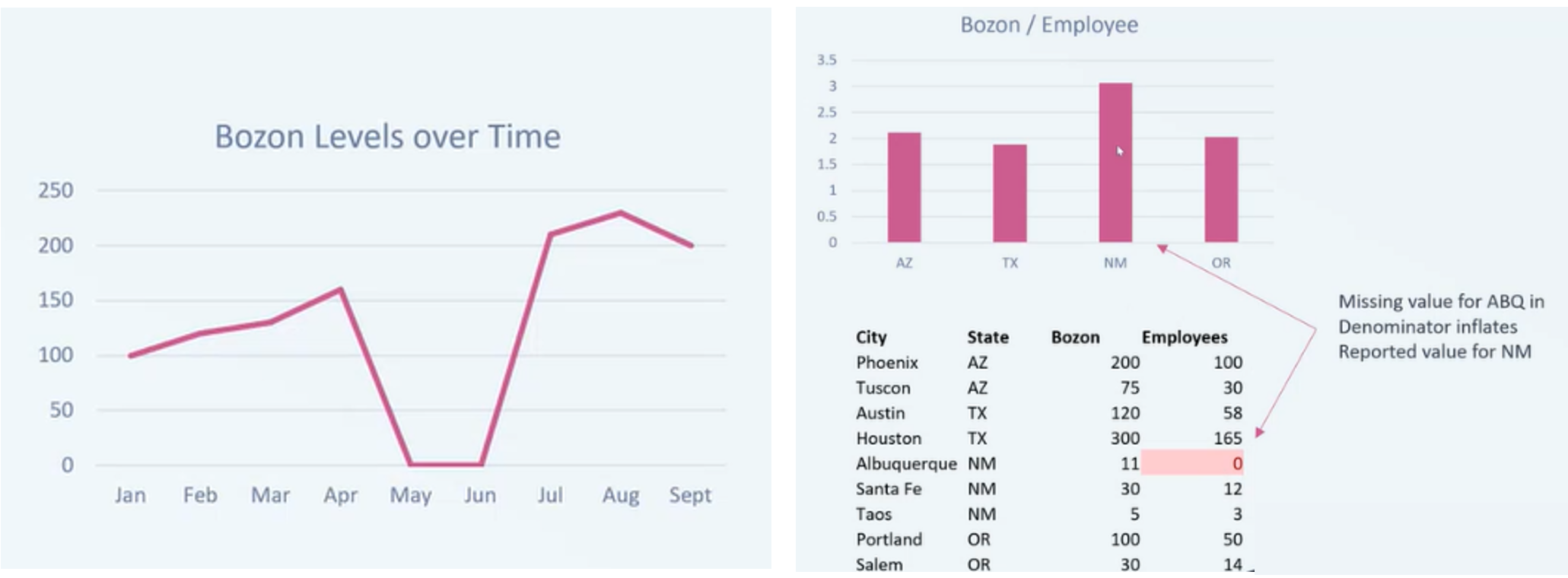
In the first example, you can see a line graph and the missing data is easy to pinpoint. In the second example, however, the missing data will only be easy to find if the numbers are off by a substantial amount. Otherwise, it is not as easy.
Types of Data Quality Issues
One of the most common and difficult-to-detect data quality challenges comes in the form of duplicate data. With duplicate data, you could be over- or under-reporting without realizing it. While this may not be a huge problem in small volumes, over time these can compound and end up skewing datasets significantly. Duplicate data in dimension tables are especially problematic, as they may result in cartesian joins and replication of duplications, or false segmentation of data. For example, if you are doing a lookup on a dimension table with duplicated data, you will inadvertently end up multiplying out the number of records across those duplicate dimensional values.
To explain further, in dimensional modeling you link data using keys. This is done so you do not store multiple copies of the same thing, which saves on space and improves retrieval efficiency (for example, in a State dimension table, you would have 1 record for New York, 1 record for California, and so on, even if you have many Sales in each state). Let’s say you want to link your sales data to your State dimension table using your State Name as a key field: if you have more than 1 record per state in your dimension table, then performing a join will duplicate your sales data for each duplicated state name.
It only takes one bad piece of data to significantly skew your results. When used in an equation or script, it is harder to catch; so it is important to perform regular sanity checks.
You may be thinking to yourself, “I am careful with my data, so I shouldn’t have any issues with bad quality,” but anyone can run into a data quality issue, even very experienced and careful data analysts. The chart below provides some insight into how and where data quality issues can happen.
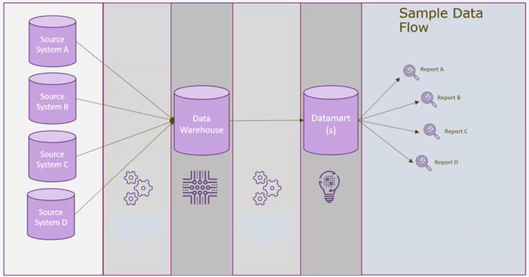
Essentially, data quality issues can happen anywhere there are people, code, and machines. Source systems can change, your ETL, data pipeline or data factories (anything that is moving data) is code that can fail. Code runs on computers and the network can fail at any given time, possibly causing incomplete or delayed data loads. There are all kinds of problems that can occur during the transport of data.
Specifically, on the inbound side, they often happen with applications. People who use the applications can cause a data issue by filling a form with strange characters or copy/pasting a huge value mistakenly, and people outside of your control who are writing code and sourcing data from you can also potentially cause problems.
On the data warehousing side, data issues can come from database administrators manually recovering data, or code that has been running consistently for years could suddenly break from an updated system library. The bottom line is that there are endless possibilities that can cause bad data and ANYTHING that touches the data has the potential to introduce data quality issues.
How to Fix Bad Data
When addressing how to fix data quality, it is important to discuss root cause analysis. Getting to the root of the issue is the first step in resolving it. After identifying the issue, it is important to ask yourself: Has anything changed? Was there a change in source systems, infrastructure, code configuration or incoming data? Have there been any process anomalies recently? Question incoming data first, especially in an established system. It will help you to get to the answer quicker.
Knowing how to identify a problem is vital. Below are a few ways this can be done:
- Automated regression tests using a golden dataset
- If there is a standardized block of data when it is run through a system, through the data chain out to a report, there are known values to be expected. These should be scheduled to be completed and checked on a regular basis.
- Sanity Checks
- Check the current values vs. the historical values to see any major discrepancies
- Specific Data Profiling Checks
- Duplicates
- Nulls
- Referential integrity
- Ranges
- Implementation Options
- Manual
- Homegrown Batch Processing
- Commercial / Existing
In addition to knowing how to identify bad data, it is critical to know ways data quality issues can be avoided. The most important one is to keep source systems from generating bad data in the first place by putting tests and checks at multiple checkpoints in the ETL process. The more you can keep bad data out of your data chain the better. Sometimes, it is not possible to do so, which is why it is vital that the issues are corrected as early and as far upstream as possible.
Here are a few other tips and tricks to avoiding data quality issues:
- Provide a feedback loop to sources, meaning the engineer who owns the code or the person who is providing the data.
- Enforce data integrity constraints in databases.
- Doing this will make it so that the database will not accept bad data. This can also be done in the ETL process or during the data migration process, this way the checks will be done for you before the data is entered into the database.
- Recovery procedure
- Documented and validated
- Defensive coding
- Anticipate issues and put the code in place for these issues.
Data quality issues happen even with careful planning, and they can cause a lot of headaches for a lot of people and can potentially cost a lot of money to rectify. So, the best-case scenario is to try and limit them from happening at all, and when fixing data issues, best practice is to fix as far upstream as possible.
The fact is: bad data happens. When it does, just remember that it happens to everyone and let your constituents know quickly, whether that’s your analysts, your business users, or your customers, and once you fix it, communicate what happened and why: it’s worth it to keep people's trust.