

This is the last of a three-part series on integrating Qlik Sense with Python (using Server Side Extensions). The first post was about some of the architecture and environment configuration and the second post was a walk-through of a simple Python SSE plugin that highlighted the important parts you’d need to change if you wanted to implement your own plugin. If you haven’t read my first two blog posts on this subject it might be worth checking them out( here and here) before reading this post. In this post, we’re going to walk through an example of a nontrivial SSE plugin that I hope highlights the potential to create awesome analytical solutions by integrating Qlik with Python. We will solve a resource optimization problem. This post will introduce the problem, the mathematical approach to solving the problem, and then ultimately what the Qlik+Python solution looks like. Lastly, I’ll wrap up by describing some limitations/quirks about the current implementation of the SSE in Qlik. The files needed are in the Toy Optimization directory on this repo (it’s the same one from the first two posts).
Problem Overview:
Imagine you are the President of a small company and you send your employees to different industry conferences throughout the year. You can usually get heavy discounts on travel by buying predefined travel packages (each with a fixed number of Plane Tickets, Boat Tickets, Train Tickets, and Bus Tickets). For example, you may have the choice between 2 or 3 different combinations of 20 tickets comprised from different modes of transportation (10/10/0/0 or 5/5/5/5 etc.). In order to save money on travel you routinely buy the packaged discounted tickets, however this brings up two challenges. First, how do you evaluate which package is better than the others? And Second, for a given package, how do you assign the tickets to your employees while taking into consideration their travel preferences? To help you make your decisions, you have asked each of you employees to rank on a scale of 1-10 their preference for traveling to the conferences by each one of those travel modes. We’ll formulate an optimization problem next that helps with your resource (in this case that’s tickets) allocation.
Mathematical Formulation:
This problem can be formulated as an integer linear program (often simply called an integer program). Integer programs are optimization problems where all the variables you are solving for are constrained to have integer values. The point of this post is not to give a lecture about linear programming, but rather to highlight a use case that can be solved by integrating Qlik and Python. What I will present next is the mathematical formulation of the problem, but first I should state in plain words what we’re trying to solve.
We’re going to set up a problem that takes the number of available tickets for each mode of transportation and our employees preferences for traveling by each of those different modes as inputs. Then we will solve for the ticket assignments under some real world constraints – namely that you wouldn’t want to assign more than a single ticket to any employee and you can’t assign more tickets than you have available.
Below, I will lay out the solution to the problem mathematically to show what calculation is being performed by the Python SSE plugin.
Let’s define a few variables first:
j =1,2,3,4 designate the mode of transportation (Plane,Train, Bus, Boat respectively)
i = 1,2,…,N designate the N employees that you are considering assigning tickets.
Rij be the preference rating that employee i has for mode of travel j
Xij be a choice variable which indicates whether or not we assign employee i a ticket for mode of travel j (e.g. X23 = 1 means that we employee 2 is assigned a ticket on mode of transportation 3). These will choice variables are what we want to solve for.
Tj be the number of available tickets for mode of transportation j.
In order to frame this as an optimization problem, we need to define some objective function. The objective function is simply the benefit that we want to maximize when making our assignments. For this problem, we know that we want to assign our employees tickets in such a way as to maximize their overall satisfaction of our employees. So, we’ll consider the sum of their satisfactions as the total satisfaction of the group. We will be solving for the ticket assignments (Xij’s) that maximize that value.
To make this more clear, lets consider the case where we have only two employees. Their preferences from the survey they filled out are below.
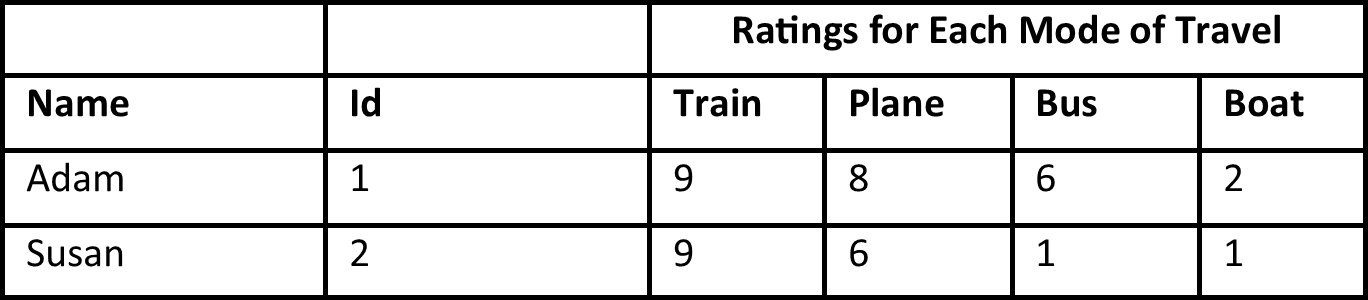
In order to maximize their satisfaction, our objective function would be:
Max(Satisfaction= R11 X11+R12 X12+R13 X13+R14 X14+R21 X21+R22 X22+R23 X23+R24 X24)
When we go ahead and plug in their ratings for each mode of transportation, that leaves us with the following equation. We need to solve for all the X’s to maximize this function.
Max(Satisfaction= 9X11+8X12+6X13+2X14+9X21+6X22+1X23+1X24)
To enforce the constraints I previously mentioned, we add a few other conditions. We know that we can only assign a single ticket to each employee. The way we enforce that mathematically is to say that only one choice variable per person can be equal to 1, and the rest must be equal to zero. That is equivalently satisfied by the following constraints:
X11,X12,X13,X14,X21,X22,X23,X24=0 or 1 (choice variables)
X11+X12+X13+X14 ≤ 1 (at most one ticket assignment for employee 1)
X21+X22+X23+X24 ≤1 (at most one ticket assignment for employee 2)
And we also know that the number of tickets assigned to each mode of transportation must be less than or equal to our total ticket capacity. The following constraints enforce that condition.
X12+X22 ≤T2 (Train tickets assigned <= Available Train Tickets)
X13+X23 ≤T3 (Bus tickets assigned <= Available Bus Tickets)
X14+X24 ≤T4 (Boat tickets assigned <= Available Boat Tickets)
So while that may seem complex, what the above formulation is doing is saying, solve for the ticket assignments (X ij) that maximize the sum of traveling preferences (our objective), subject to the facts that one employee can be assigned to no more than one ticket, and we cannot assign more tickets than are available for each mode. When we solve for the X ij that maximize that objective function, we will have determined the best set of people to assign to which mode of travel given your constraints.
This problem can be written more succinctly (for an arbitrary number of N employees) as follows (Note:∀ just means for all):
Maximize:
![]()
Subject to the constraints:

Ours is designed to solve this problem.
Plugin Design
We’ll call the function “OptimalAssignments” since it will calculate the optimal assignment of tickets to employees according to the objective we just defined – the sum of the preference scores. Within Qlik, the function will take the Employee IDs that we want to consider for assignment and the number of tickets we have available (the Tj‘s in the above problem formulation) as inputs. It will return a column of string results, with each string representing which ticket assignment is optimal for each employee. The Function Definitions JSON file is shown below. Based on the description of the Function Definitions JSON from the last post, we can see that the function is a Tensor (type 2) that will return a string variable (key = 0), and will take five numeric (key = 1) inputs.
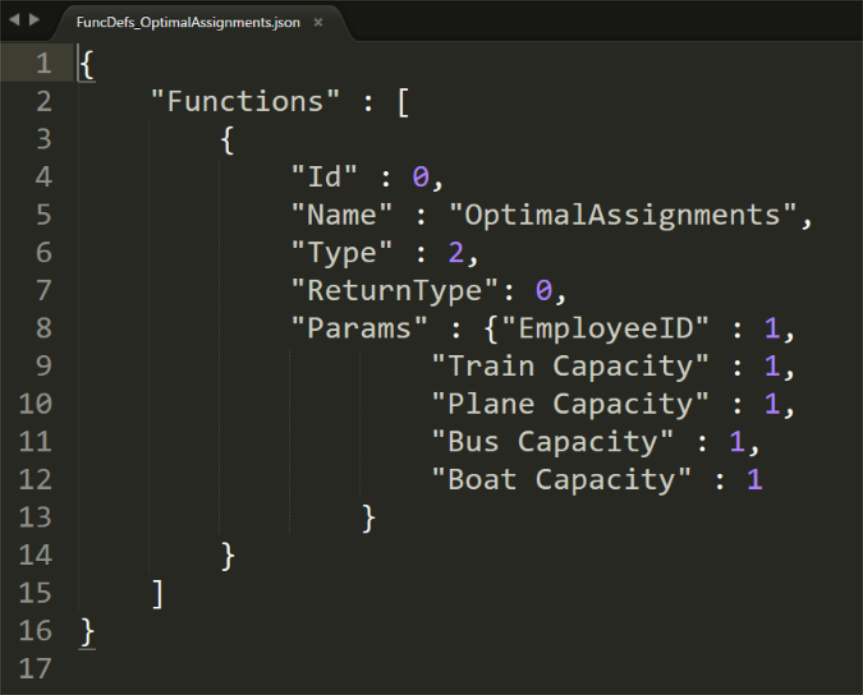
Before we dive into exactly how the plugin functions, I want to highlight one important design consideration that was already made. Did you notice in the mathematical formulation of the optimization problem in the preceding section, we need to know all the R ij values – how each employee rates their preference for each transportation option. And yet that data is not being used by the function. What gives, right?
There was one primary reason that was done. When passing potentially large amounts of data for serialization and de-serialization between Qlik and Python, the less data we have to pass, the more responsive the RPC will be. For that reason, we chose to have all the employee preference information already stored (in memory) within the Python Plugin. In this manner, Qlik passes the list of IDs and the capacity (ticket) constraints in the request, and Python uses those values to make the appropriate selection of employee preferences within the Plugin before formulating the optimization problem. This process is shown schematically below:

You may have noticed something else a little interesting in the schematic above. The available Tickets quantities– passed from Qlik – are repeated on every row of the data. This is not an error in what I am documenting, but rather a limitation with Qlik’s present SSE integration that we’ll discuss at the end of this post. Basically, Qlik cannot pass scalar arguments in a Tensor function.
Optimization Implementation
The optimization problem is formulated and solved in Python using a package called pulp. It’s an optimization package that is freely available for use. Additionally, the pandas package is used for some data manipulation. If you don’t have those packages installed, and you want to follow along or use this app on your local machine you will need to install them.
pip install pandas pulp
Now I’m not going walk through the code line by line as that would be overly tedious and complicated – not to mention boring. What I will do, however is point out the two sections of the code that handle the implementation.
The first is within the __init__ method, which starts on line 25 of the ExtensionService file. I have added some code that binds the all the Employees IDs and travel preferences data to the plugin when the plugin is started (lines 38-61). This prevents us from 1) having to send all the data from Qlik as previously mentioned and 2) prevents us from needing to read in the preferences data (from disk) every time Qlik sends a new request. The most important thing we’re doing here is creating a dictionary of employee IDs and their preferences for each travel mode so that those values can be easily (and quickly) accessed when formulating the optimization problem. Follow the comments in the code to understand what it is doing. If you have any questions, reach out and I’m happy to help.
The second major modification to the code is in the actual implementation of the custom function, OptimalAssignments. This is between rows 81 and 163. Again, I’m not going to go over the exact code details here. The code is well documented, if you get stuck reach out. The important thing is that in this section, Python is taking the request being sent from Qlik (to execute the function), using the IDs and ticket quantities from Sense to select the appropriate data that was loaded in the __init__ method. Using this data, an optimization problem (the same one from above) is being formulated and solved by Python. Once its solved, the data is passed back to Qlik. Each time you make selections in Qlik, a new optimization problem is formulated and solved.
Employee Assignment Optimization – Python SSE Plugin.qvf
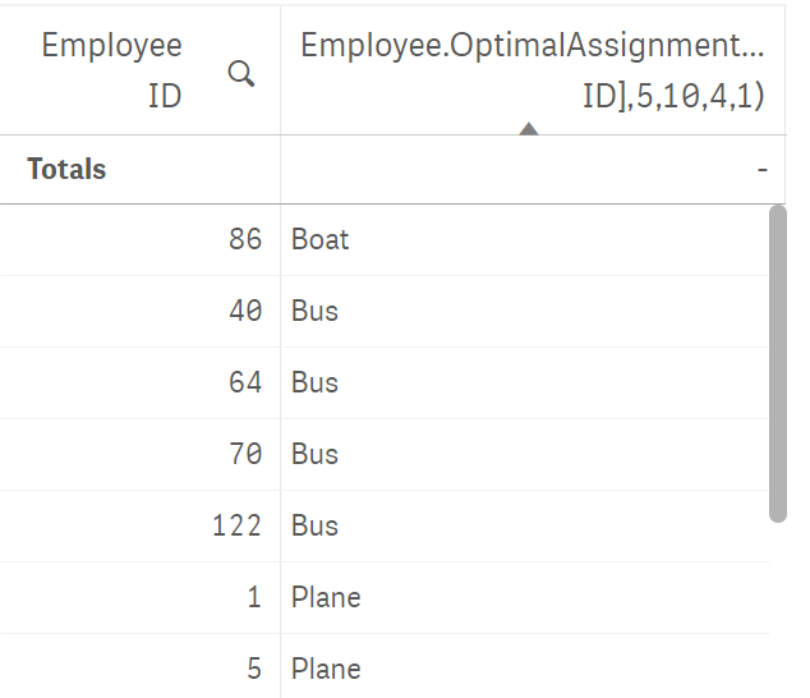
Recall from the last post that you need to make sure you run the ExtensionService_OptimalAssignments.py prior to opening Qlik Sense. When you open the application, you’ll see three sheets. The first sheet explains the problem that we’re actual solving. The second sheet shows how you can call the custom function. Remember from Part 1 of this blog series that we aliased port 50056 with the name Employee (within the Settings.ini file). To call the function we use Employee.OptimalActions([EmployeeID],5,10,4,1). What is happening is that the Python SSE plugin is formulating and solving the optimization problem for the current selected employees, assuming there are 5, 10, 4 and 1 train, plane, bus and boat tickets respectively. If you make a different selection of employees, the plugin will formulate and solve a new problem and the optimal results will update in the front-end. If the you want to change the available tickets – maybe dependent on regions or some other dimension – you must go into the table object and update the last 4 parameters within the expression manually. That is not the most user-friendly thing to implement this solution.
If we wanted to take it a step further (which we do), we could variablize the ticket quantities being passed into the function and use input boxes on the front-end to define what those available ticket quantities are. This is precisely what is implemented on the third sheet. Note that this sheet does require a Qlik Sense Extension object (it’s called inputVariable) to function properly. A copy of that plugin is included in the git repo.
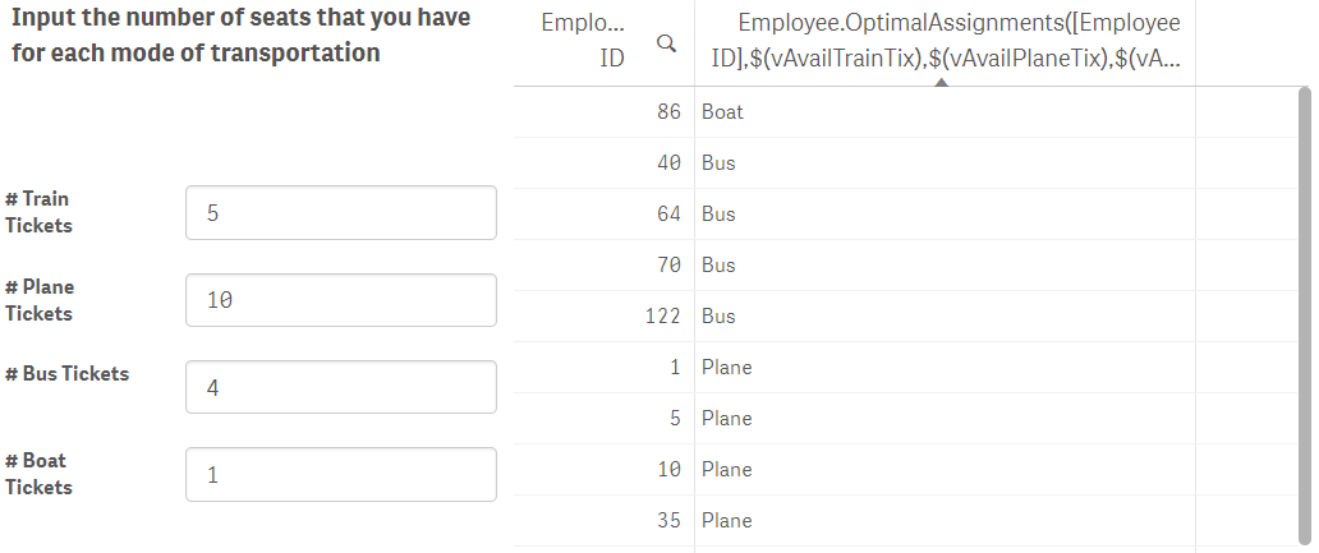
Now, our finished product is an application that any business user can easily access to solve the optimal assignment of tickets. This highlights the true benefit with this integration of Qlik and Python – the technical/mathematical components of a challenging problem have been abstracted away from the user so that all they must do is interact with a simple intuitive dashboard. So long as they know which employees they want to consider and how many tickets are available they can make a more informed, analytically driven decision.
SSE Limitations
Now that we’ve gotten a solid use-case under our belt lets level set for a minute. There are a few limitations and quirks with the Server Side Extensions right now. It is worth knowing what some of these limitations are as you begin to think of use cases for the SSEs.
- Multiple columns of data cannot be passed back from one RPC at the time of writing this article. For example, consider the optimization problem we solved. Each time the problem is formulated and solved, Python has calculated the best ticket assignment, the employee preference score for that assignment, and even the total sum of preferences for the assigned tickets (the objective function). Right now, if we want to view all that information, we need to make three separate function calls – once to return the ticket assignment, once to return the preference for that assignment, and once to return the value of the objective function. What this means is that the optimization problem must be formulated and solved three times instead of one.
- Another issue – I don’t know if I want to say limitation – is that scalar values, like the ticket availabilities from the example in this blog post are repeated on each row of the request. It would be an improvement if Qlik could pass all the scalar values once and the tensor values (column of Employee IDs) once to reduce the sending of duplicate data. Again, this is not so much of a limitation as it is a current quirk.
- Right now, SSE are only available for Qlik Sense – Sorry Qlik View Users. The good news here is that Qlik is trying to get this functionality for Qlik View by the end of 2017 – so it’s not too far off.
- Depending on how much data you send to your plugin in a request, and what it is you are asking the plugin to do, computation times within the plugin can affect the responsiveness of the application. This has nothing to do with Qlik, but it’s something to be aware of.
- Right now, the execution of the custom functions is always enabled. What this means in the context of our application is that if you wanted to change the number of available tickets for each mode of transportation, you would trigger four separate optimizations. Each time you entered an input, the optimization problem is formulated and solved – even though you might only want to trigger the process when you have adjusted all the input variables. There are some workarounds for this, some of which rely on custom extensions, some which require clever coding in your plugin. This problem becomes more noticeable when the computing times are non-negligible. If it takes 15 seconds to return a single result set, it would be nice to have your inputs all set before committing to trigger the computation.
- Because the SSE performs calculations and returns calculated fields, the results are not selectable, filterable etc. The results are not part of the data model. They can be sorted, alphabetically or numerically, but that’s about it. With the optimization problem we just solved it would be great to analyze how many tickets were assigned across departments, regions, etc.. To work around this in some related use cases we have worked on, we have incorporated a partial reload that makes the calculations part of the data model.
The good news here is that Qlik really cares about what the community has to say about the SSE. They are working on some of these issues and are eager to hear how they can make SSE better.
Summary
In this post, we discussed a very simple resource optimization problem, walked through the mathematical formulation that we can use to solve the problem, took a look at some technical considerations for the plugin implementation, and looked at the actual application where this plugin is being used. While the problem here is a somewhat silly one related to assigning tickets to employees, the same approach can be extended to apply work shifts to employees, or nurses to particular patients, or any other problem where you need to optimally allocate finite resources. Lastly, we talked about some limitations with the way the SSE are currently setup. I do want to take the opportunity to say unequivocally that even with the limitations mentioned in this post, Server Side Extensions are a very welcome addition to the data analytics arsenal. Kudos to Qlik for a great first implementation. Make sure to let them know if you have feedback – they are genuinely interested in making this as useful as possible. Also, if you are interested in more details about these posts or any of the code feel free to reach out to me (Twright@axisgroup.com). If you are interested in more details about Server Side Extensions, check out Qlik’s documentation. There is a lot to sift through but the information is very helpful.